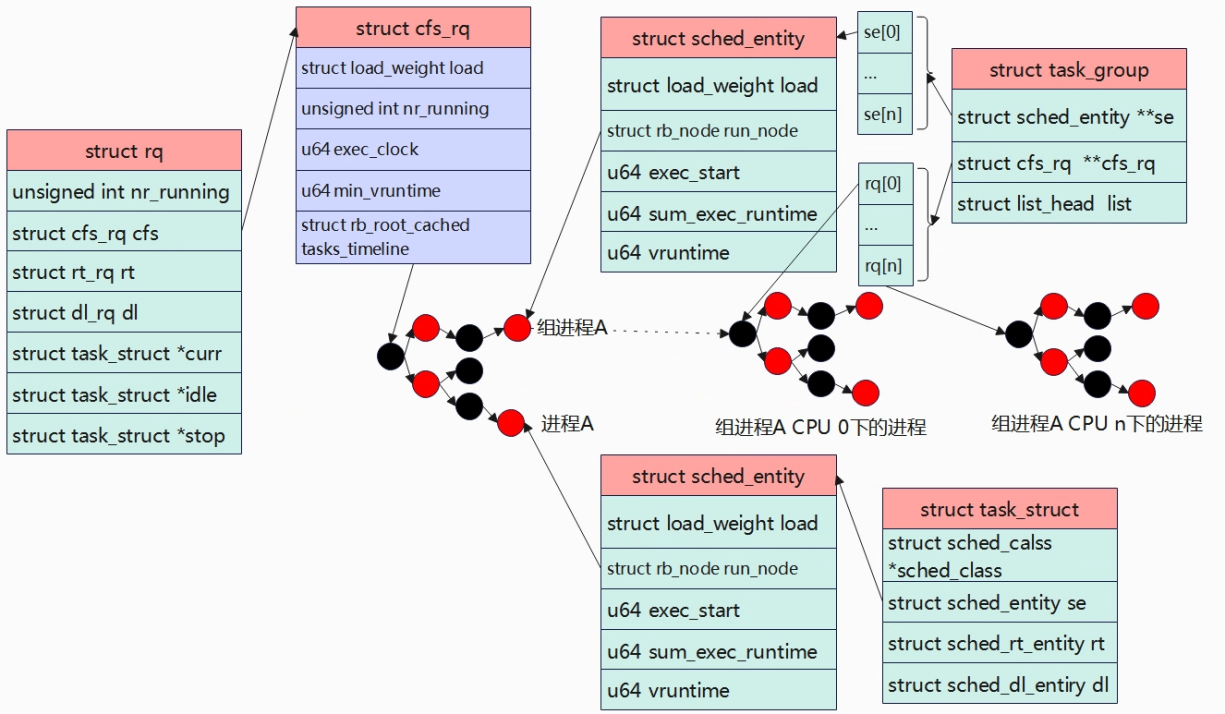
数据结构 如果一个用户创建了大量进程,由于CFS的机制,这些进程会和其他用户的进程按照优先级对应比例瓜分CPU时间,最总导致这个用户占用过多的CPU时间。引入组调度后,就可以按照任务组的粒度来平分CPU时间,防止以上的问题出现。struct task_group用于描述一个任务组,裁剪后的数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct task_group {#ifdef CONFIG_FAIR_GROUP_SCHED struct sched_entity **se ;struct cfs_rq **cfs_rq ;unsigned long shares;#endif struct list_head list ;struct task_group *parent ;struct list_head siblings ;struct list_head children ;#ifdef CONFIG_SCHED_AUTOGROUP struct autogroup *autogroup ;#endif
se[i] 表示这个task_group在第 i 个 CPU 上的 调度实体, 该se代表的也是一个任务组。
cfs_rq[i]指向这个任务组在第i个CPU上的rq,组织这个任务组在该CPU上的任务,也等于se[i].my_rq
sched_entity结构体如下,通过my_q可以判断一个调度实体是否是任务组,如果该为 NULL, 则表示一个任务,否则就是一个任务组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct sched_entity {struct load_weight load ;struct rb_node run_node ;struct list_head group_node ;unsigned int on_rq;struct sched_statistics statistics ;#ifdef CONFIG_FAIR_GROUP_SCHED int depth;struct sched_entity *parent ;struct cfs_rq *cfs_rq ;struct cfs_rq *my_q ;unsigned long runnable_weight;#endif
内核有一个全局链表task_groups,新创建的task_group会添加到这个链表中;全局根节点struct task_group root_task_group以及
创建任务组/添加任务 cpuset相关函数handler如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct cgroup_subsys cpuset_cgrp_subsys = {.css_alloc = cpuset_css_alloc,.css_online = cpuset_css_online,.css_offline = cpuset_css_offline,.css_free = cpuset_css_free,.can_attach = cpuset_can_attach,.cancel_attach = cpuset_cancel_attach,.attach = cpuset_attach,.post_attach = cpuset_post_attach,.bind = cpuset_bind,.fork = cpuset_fork,.legacy_cftypes = legacy_files,.dfl_cftypes = dfl_files,.early_init = true ,.threaded = true ,
通过cgroup的接口可以很方便地创建一个调度组,对应内核代码流程为:
1 cgorup_mkdir ->cgroup_apply_control_enable ->cpuset_css_alloc ->
往一个任务组添加任务流程如下:
1 cgroup_file_write ->cgroup_attach_task ->cgroup_migrate ->cgroup_migrate_execute ->cpu_cgroup_attach ->
调度逻辑 组调度并没有改变太多的CFS调度逻辑,下面主要分析下选任务和时间分配相关变更:
摘取核心逻辑如下,如果se的cfs_rq是NULL,代表这个se是一个任务,因此不进入循环;对于任务组,会一直循环cfs_rq里的se,直到找到一个se是一个任务。
1 2 3 4 5 6 7 8 9 10 11 12 struct task_struct *pick_next_task_fair (struct rq *rq, struct task_struct *prev, struct rq_flags *rf) {struct cfs_rq *cfs_rq =struct sched_entity *se ;struct task_struct *p ;do {NULL );while (cfs_rq);
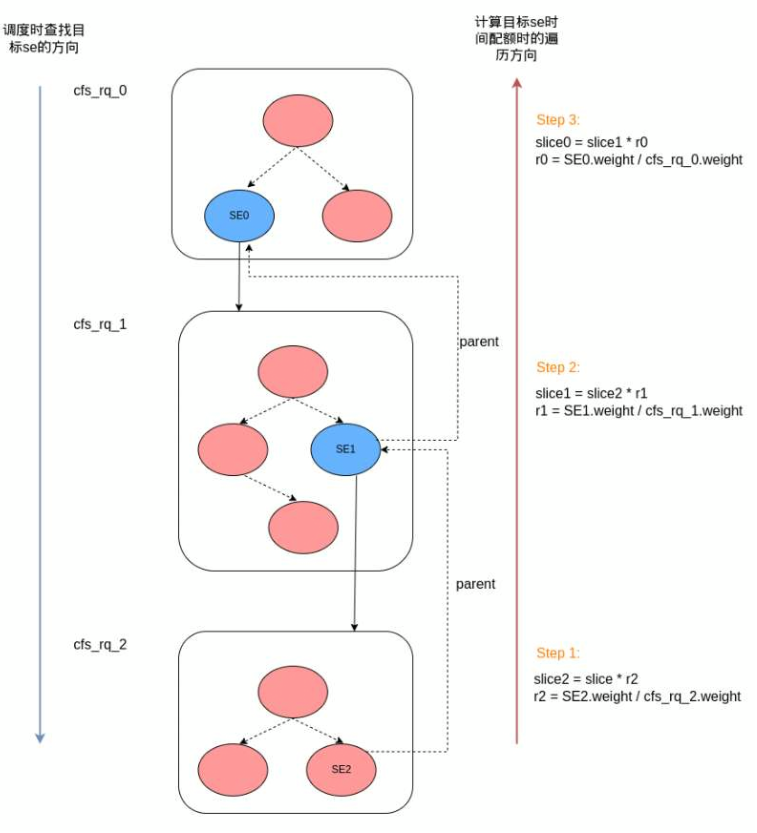
如果se代表的是任务组,那么该se在当前cfsrq中根据任务组的时间份额进行二次分配。相关函数是 sched_slice,采用自下而上的方式遍历整个cfs_rq。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define for_each_sched_entity(se) \ for (; se; se = se->parent) static u64 sched_slice (struct cfs_rq *cfs_rq, struct sched_entity *se) struct load_weight *load ;struct load_weight lw ;if (unlikely(!se->on_rq)) {return slice;
如下示意图很清楚地解释了计算过程,最终SE2的时间为slice * r2 * r1 * r0,也很容易理解,因为r0 * r1 * r2就是SE2在整个cfs_rq里的权重占比。
参考文档
Linux Source V5.10 Linux 内核的 CFS 任务调度 Linux核心概念详解 Linux进程调度-组调度及带宽控制