[OSDI论文阅读] Harvesting Memory-bound CPU Stall Cycles in Software with MSH
前言
在经典论文 A Top-Down Method for Performance Analysis and Counters Architecture 里,Ahmad Yasin提出了一种Top-Down的方法,基于微架构分析软件性能,把CPU流水线划分为4个部分:
Frontend Bound, CPU流水线的前端部分(instruction fetch,指令解析等),由i-cache miss, i-TLB miss等原因造成;
Bad Speculation,投机失败导致的流水线被浪费,如分支预测错误情况;
Retiring 即正常结束的指令,理论上越高代表程序性能越好;
Backend bound 流水线后端部分,可分为Core Bound和Memory Bound,前者偏向于计算单元,后边偏向于由内存访问导致的执行停顿。
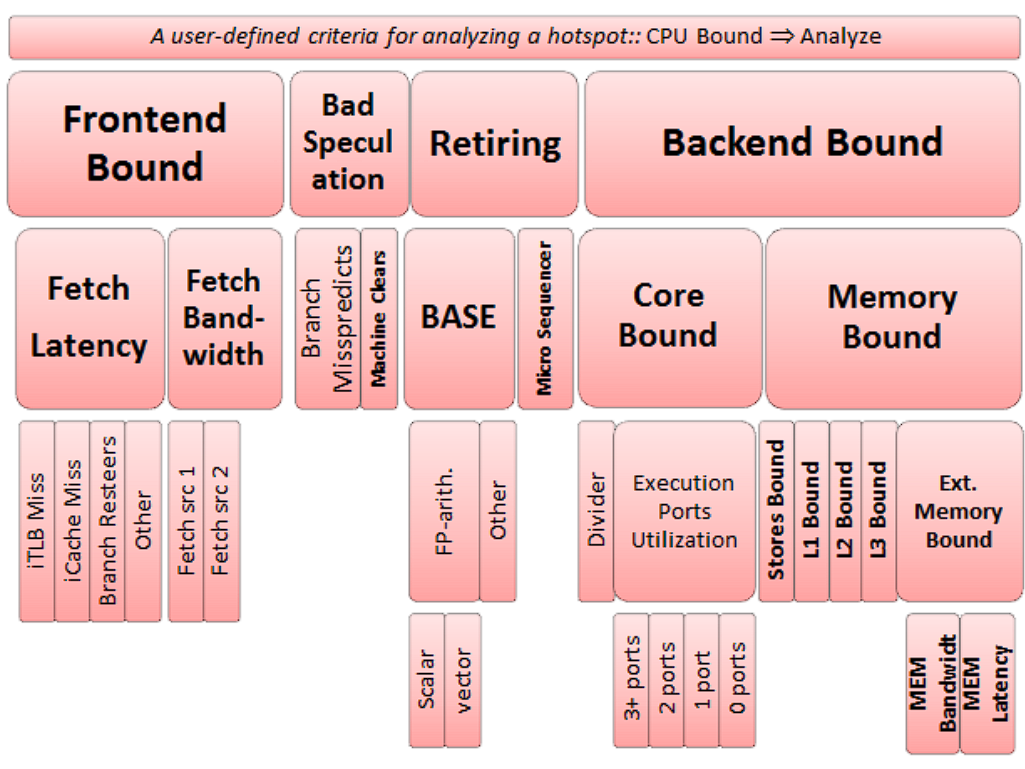
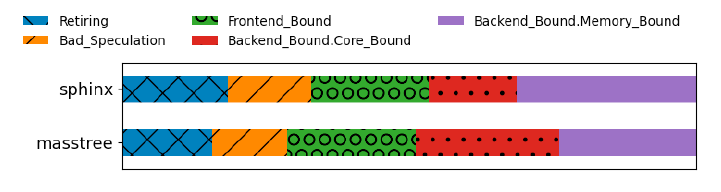
本文分析sphinx和masstree软件性能后,发现Memory Bound对两个软件的性能影响最大,在总cycle中的占比分别为25%和31%。
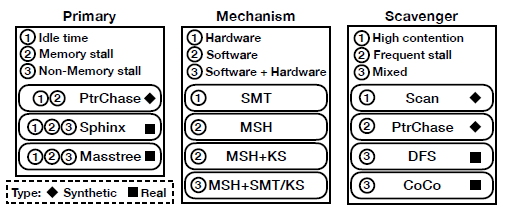
常见的降低Memory-bound Stall Cycles的解决方法为SMT(simultaneous multithreading),即在一个物理核里有两个线程,共享一部分资源(ALU, FPU, cache等),当其中一个线程发生Memory-bound时,另一个线程便可以利用这些共享的单元,提高流水线的利用率。然而SMT技术也存在不足,比如不可配置,如给定一个SLO,无法在Primaries的延迟和Scavengers的吞吐量之间进行权衡;此外,SMT 也无法完全捕获受Memory Bound导致的的stall cycle,尤其是当并发线程频繁发生cache miss时。这是因为主流的 2 宽度 SMT 没有足够的并发度来捕获大部分Memory stall,虽然可以通过 SMT 的宽度来解决此问题,但需要增加更多硬件资源,而且还加剧了延迟开销问题。
于是文章提出了一种名为MSH (Memory Stall Harvesting)的软件技术,利用Memory Bound导致的CPU stall cycle来执行额外的指令,针对SMT在Memory Bound方面的不足,用巧妙的软件设计降低了Memory Stall数量。
设计思路
文章中高频出现两个词,在此做一下解释:
- Primaries,指主程序;
- Scavengers,清理程序,主程序的协程,在特定时机(如mem stall)切换到清理程序执行。
MSH设计可分为3部分:
Profile
Binary Instrument
Runtime Scheduling
整体流程如下图:
Profile
首先在离线阶段使用性能剖析工具 (本文使用PEBS, LBR, perf)对程序进行性能分析,针对Load指令导致的Memory-bound进行评估,主要考虑L2/L3 cache misses率以及代码块的执行次数。根据以下2条逻辑选取符合条件的Load指令:
筛选cache miss率高于阈值的Load指令
通过如下公式来评估一条Load指令开销:
$$
Latency Overhead=Instruction Frequency×Cache Miss Rate×Memory Access Latency
$$
Binary Instrument
即二进制插桩,MSH会在程序二进制中适当位置插入指令,对Primary和Scavengers都需要进行插桩。
Primary instrumentation
完成Profile后,在选取出来的Load指令前插入一条software prefetch指令,以及一条yield指令。在Runtime阶段,遇到开销较大的Load指令时,由于已经提前做了插桩操作,会将Load访问的地址预取到cache中,同时切换到scavengers线程执行,待合适时机再切换会primary线程,此时cache预取已完成,数据已经在cache中了,就不会导致memory stall出现影响性能。
Scavenger instrumentation
Scavenger插桩和Primary 方法相同,都是基于Profile的结果,在Load之前插入yield指令,并切换回Primary。有所不同的是,如果两个yield点过于靠近,第二条yield指令会切换到另一个Scavenger程序,而不是Primary。这是因为如果两条yield指令过于靠近,此时Primary的cache prefetch都还没完成,切换回去会导致memory stall,因此切换到另一个Scanvenger程序来避免此问题。
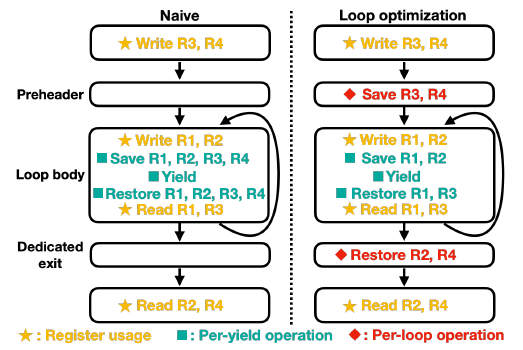
此外,由于协程切换需要保存上下文,为了减少这部分开销,MSH对循环的代码做了优化,仅对会发生修改的寄存器进行保存恢复操作,例如下图中的循环体中未操作R3和R4寄存器,因此在Loop body里进行协程切换时无需对这两个寄存器进行保存和恢复。
Runtime Scheduling
基于以上的分析,MSH必然还涉及Primary和多个Scanvenger的调度,线程管理,资源分配等问题。主要包含如下流程:
Scanvenger初始化,在分配Scanvenger给Primary之前,会对Scanvenger进行初始化,包括加载Scanvenger代码,申请栈空间,设置返回地址。
Scanvenger窃取,在给Primary分配一个Scanvenger前,会优先从其他Primary那里窃取Scanvenger,避免重新建立一个新的Scanvenger带来开销。之所以可以被窃取,是由于在线程阻塞或者被终止时会被设置stealable的标志位。
Scanvenger获取,当没有stealable的Scanvenger时,会从Scanvenger pool中分配一个,当然分配完成后仍然需要初始化。
核心伪代码如下:
1 | |
性能测试
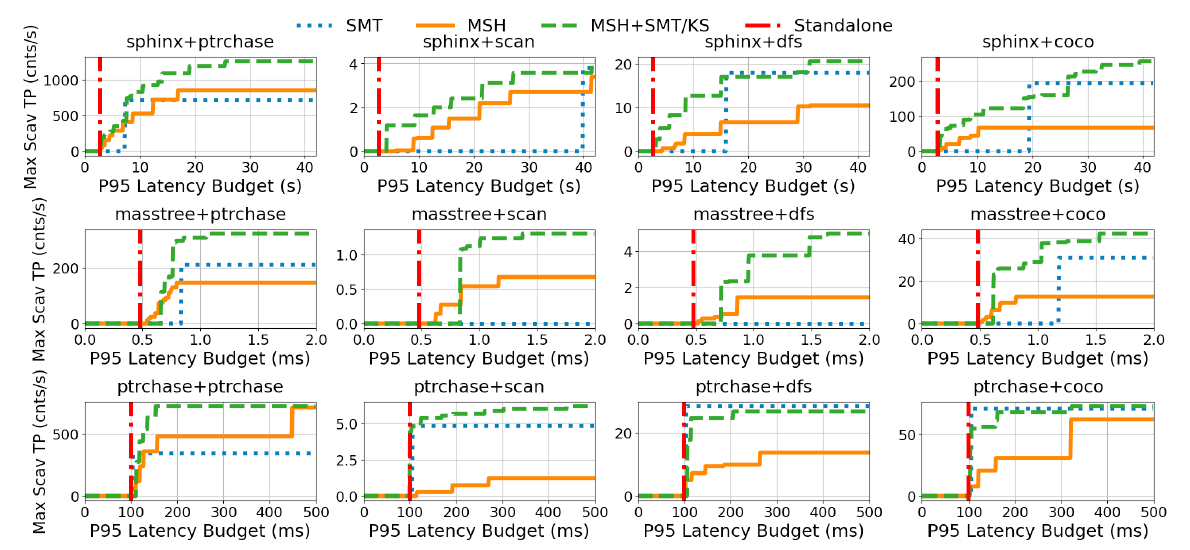
- 在关闭SMT的场景,MSH可实现接近SMT 72%的scavengers吞吐量
- 如果给出更宽松的延迟 SLO,MSH 可以进一步权衡primary的延迟和scavengers吞吐量
- 相比SMT,当scavengers也处于停滞时,MSH 可以充分收集mem stall cycle,并且实现高达 2 倍的吞吐量。
总结
文章提供了一个很新颖的软件思路,来降低Memory Bound对程序性能带来的影响,实现了类似SMT的效果。文章的代码已开源,看了下里面的scavengers是一段无意义的计算程序,和Primary业务程序并没有关联,因此仅仅是减小了memory stall的cycle,并没有实际提高Primary的性能。这个方案实际应用到优化具体业务性能仍然很困难,因为scavengers的代码需要是有意义的,能够在Primary发生memory bound时处理一些辅助任务,因此需要精心构造才行,这部分文章并没有体现。
References
Harvesting Memory-bound CPU Stall Cycles in Software with MSH